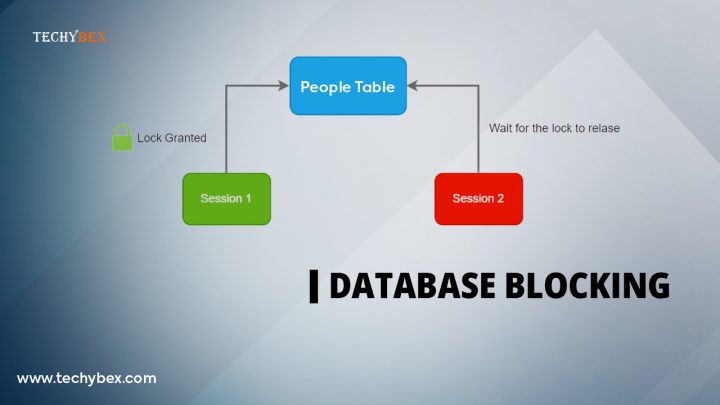
SQL Server uses locks to maintain data integrity for reads as well as writes and allows only one process to have control of the data at a time. Different types of locks such as Shared, Update, Exclusive, and Intent are used by the SQL server where each lock has different behavior and effect on data. Database blocking is caused when locks are held for a long time indicating that one process has to wait for the other process to finish with the data and then release the lock for the second process to continue. Though blocking is similar to deadlocking but blocking is quickly resolved as soon as the first process releases the resource.
Explanation
Blocking in a database occurs when one session holds a lock on a specific resource and a second process tries to acquire a conflicting lock on the same resource. Usually, the first process locks the resource for a small time and when the lock is released by the owning session then the second connection is free to acquire its own lock to continue processing. This behavior is normal and occurs several times a day with no major effect on the system’s performance. Hence it can be said that blocking occurs when two processes wish to access the same data but the second process has to wait for the first process to release the lock. Blocking is not usually visible because locks are held for a very small time. Locks are also used while updating or reading the data, in the case when data is updated an Update lock is used and when data is read a Shared lock is used. An exclusive lock on the data is created by an Update lock and on the other side to read the data a Shared lock happened and it stay compatible with other processes using a Shared lock to access the data. When the two processes try to access the same data then locking and blocking occur.
What causes Blocking?
Blocking problems in databases usually occur due to poor application design. While designing the database, several normalization rules need to be adhered to. The normalization rule indicates that redundant data should not be kept in the database and transactional databases should not have any repeating columns and every data should be stored only once. This allows locks to be quickly released. Some of the other causes of blocking include:
- Blocking problems are also caused due to the lack of appropriate indexes. In a transaction that modifies several rows of a table without a clustered index then the SQL server may acquire a table lock for the entire transaction duration. The rest of the transactions will be blocked until the first transaction is committed or rolled back.
- Another common cause of blocking is poorly written transactions because such transactions ask for an input value from a web screen or GUI in the middle of a transaction.
- Another cause of blocking can be the inappropriate use of locking. Suppose a SQL server is forced to acquire 50000-row level locks then transactions may have to wait until other transactions are complete.

Make use of SQL Monitor to Monitoring and Troubleshoot Blocking
A less-reactive monitoring solution that immediately alerts for severe blocking should be set up to provide sufficient information to diagnose and resolve it quickly. This monitoring solution must also allow us to see what type of blocking occurred, as well as when and where it occurred. This leads to quick action for blocking before it gets severe and starts affecting performance and alerts. A blocking process alert is raised by the SQL Monitor against any process that has been blocking one or more processes for longer than a specified duration. In case blocking exceeds one minute, then by default, a low severity alert is raised but with SQL Monitor alert, multiple levels of alerts can be set for different thresholds. Thus, long-running query alerts can be seen related to any blocked-process queries.
Troubleshooting Blocking
Irrespective of the blocking condition, the same methodology is used for troubleshooting the blocking. At first, the head blocker should be identified, find what the query is doing, and determine the reason for its blocking. After identifying the problematic query, the next step is to analyze and determine the reason behind the blocking. After knowing the reason, changes can be made by redesigning the query and the transaction.
Troubleshooting Steps
- Identify the head blocker or the main blocking session
- Determine what is holding locks for an extended period and also the query and transaction that is causing the blocking
- Understand or analyze the reason behind the occurrence of extended blocking
- Redesign query and transaction to resolve to block
Write SQL scripts that constantly monitor the locking and blocking state on the SQL server. Then the common blocking scenarios should be identified and resolved and the script output should be constantly checked. Then the SQL profiler’s data need to be regularly examined to detect blocking.